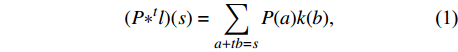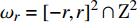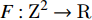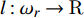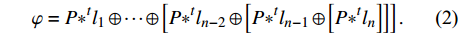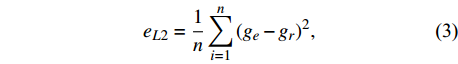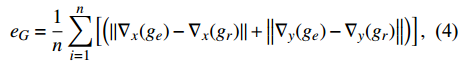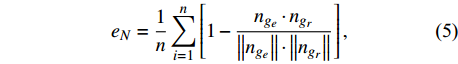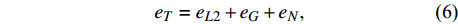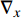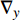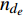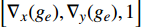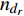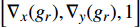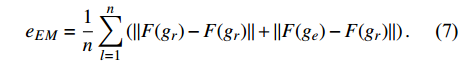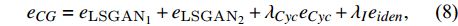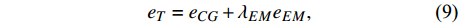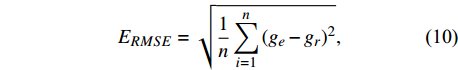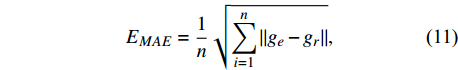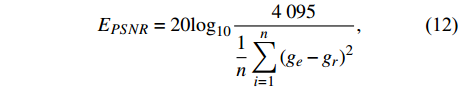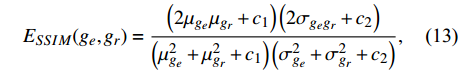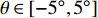Hamed Amini Amirkolaee, Hamid Amini Amirkolaee. Medical image translation using an edge-guided generative adversarial network with global-to-local feature fusion[J]. The Journal of Biomedical Research, 2022, 36(6): 409-422. DOI: 10.7555/JBR.36.20220037
Citation:
Hamed Amini Amirkolaee, Hamid Amini Amirkolaee. Medical image translation using an edge-guided generative adversarial network with global-to-local feature fusion[J]. The Journal of Biomedical Research, 2022, 36(6): 409-422. DOI: 10.7555/JBR.36.20220037
Hamed Amini Amirkolaee, Hamid Amini Amirkolaee. Medical image translation using an edge-guided generative adversarial network with global-to-local feature fusion[J]. The Journal of Biomedical Research, 2022, 36(6): 409-422. DOI: 10.7555/JBR.36.20220037
Citation:
Hamed Amini Amirkolaee, Hamid Amini Amirkolaee. Medical image translation using an edge-guided generative adversarial network with global-to-local feature fusion[J]. The Journal of Biomedical Research, 2022, 36(6): 409-422. DOI: 10.7555/JBR.36.20220037
Hamed Amini Amirkolaee, School of Surveying and Geospatial Engineering, College of Engineering, University of Tehran, N Kargar street, Tehran 1417935840, Iran. Tel/Fax: +98-930-9777140/+98-21-88008837, E-mail: hamedamini.a.k@gmail.com
In this paper, we propose a framework based deep learning for medical image translation using paired and unpaired training data. Initially, a deep neural network with an encoder-decoder structure is proposed for image-to-image translation using paired training data. A multi-scale context aggregation approach is then used to extract various features from different levels of encoding, which are used during the corresponding network decoding stage. At this point, we further propose an edge-guided generative adversarial network for image-to-image translation based on unpaired training data. An edge constraint loss function is used to improve network performance in tissue boundaries. To analyze framework performance, we conducted five different medical image translation tasks. The assessment demonstrates that the proposed deep learning framework brings significant improvement beyond state-of-the-arts.
Medical imaging is a very important technique for diagnosing and when treating numerous diseases. Generally speaking, using a single imaging modality is insufficient in clinical decision-making and it is necessary to combine different modalities. Each modality has unique features with varying degrees of sensitivity and specificity, therefore set of images is required for accurate and reliable clinical decisions. A desirable approach for many diagnostic and therapeutic purposes is to generate synthesized hypotheses using medical images and image translation such as computed tomography (CT) to magnetic resonance imaging (MRI).
The traditional approach to image translation can be categorized as either atlas-based, tissue-segmentation-based, or learning-based approaches[1]. In atlas-based approaches, an image registration method is applied to align an MRI to an atlas MRI for approximating a correspondence matrix. The approximated matrix can be used to estimate query MRIs by warping the associated atlas CT image[2–4]. These approaches require an accurate deformable image registration of the atlas and patient MRIs. In tissue-segmentation-based approaches, MRI voxels are segmented into different tissue classes, i.e., soft tissue, fat, bone, and air. Then, class segments are refined manually[5–6]; however, using only one MRI is not sufficient to separate all major tissue types. Additionally, MRI sequences cannot be used to reliably differentiate bone from the air. Therefore, most tissue-segmentation-based approaches require multiple MR sequences, which prolong image acquisition times and create a more complicated workflow[1]. In learning-based approaches, the features of two different domains are extracted, and then a non-linear map is generated using statistical-based learning or model fitting techniques. Huynh et al iteratively translated MRI patches into the related CTs by employing a random forest algorithm in conjunction with an auto-context model[7]. Zhong et al estimated pseudo-CT images from MRIs using the k-nearest neighbor regression algorithm[8]. They employed a supervised descriptor learning based on low-rank approximation to optimize the local descriptor of an MR image patch and to reduce its dimensionality.
Deep learning has been found to achieve the best accuracy in a number of different fields without the need for handcrafted features. This has led to the more widespread use of these networks in medical image analysis[9–10]. In one particular case of image synthesis, Han et al utilized a deep neural network that is architecturally similar to U-Net and can be trained to learn direct end-to-end mapping using MRIs with related CTs[1]. In a similar study, a generative adversarial network (GAN) was used to estimate CTs using MRIs and a fully convolutional network was designed which incorporated an image-gradient-difference-based loss function to avoid generating blurry target images[11]. Dar et al proposed a new deep approach for multi-contrast MRI synthesis based on conditional GAN to preserve intermediate-to-high frequency details via an adversarial loss[12]. They tried to enhance the performance with a cycle-consistency loss for unregistered images and a pixel-wise loss for registered images. Wang et al improved the discriminator attend for specific anatomy with an attention mechanism using selectively enhanced portions of the network during training[13]. Upadhyay et al presented an uncertainty-guided progressive learning scheme for image translation by incorporating aleatoric uncertainty as attention maps for GAN training in a progressive manner[14]. Dalmaz et al proposed a different GAN that utilized an aggregated residual transformer to combine residual convolutional and transformer modules[15]. They tried to promote diversity in captured representation using residual connections and distill task-relevant information using a channel compression module.
In the aforementioned methods, estimating synthetic images requires those images from the source modality and their related images in the target modality, which is referred to as paired data[16–17]. Providing paired data is particularly challenging because patients should undergo both MRIs and CTs and there should not be a delay between the images. Additionally, if training with unpaired data is possible, the amount of available training data increases[17]. Wolterink et al employed a GAN to be trained using unpaired CT images and MRIs[18]. In another study, Yang et al utilized a cycle generative adversarial network (CycleGAN)[19] to estimate CT images using MRIs with a structure-consistency loss based on the modality of independent neighborhood descriptor[16]. The performance of these networks was analyzed in some specific tasks, which is not enough to demonstrate their generalizability.
In this study, a different edge-guided GAN, herein referred to as the edge-guided generative adversarial network (EGGAN) framework, is proposed for medical image-to-image translation. As paired data is difficult to obtain, we attempt to develop a framework based on unpaired data. The main contributions of this paper are as follows: (1) A different GAN based on edge detection is proposed for medical image-to-image translation using unpaired training data which utilizes an edge detector network to improve the estimated image structure; (2) A global-to-local feature fusion approach is proposed to extract and fuse local and global information progressively into the encoder-decoder deep network; (3) Network performances are assessed under different challenging medical scenarios and then compared with other deep approaches.
Materials and methods
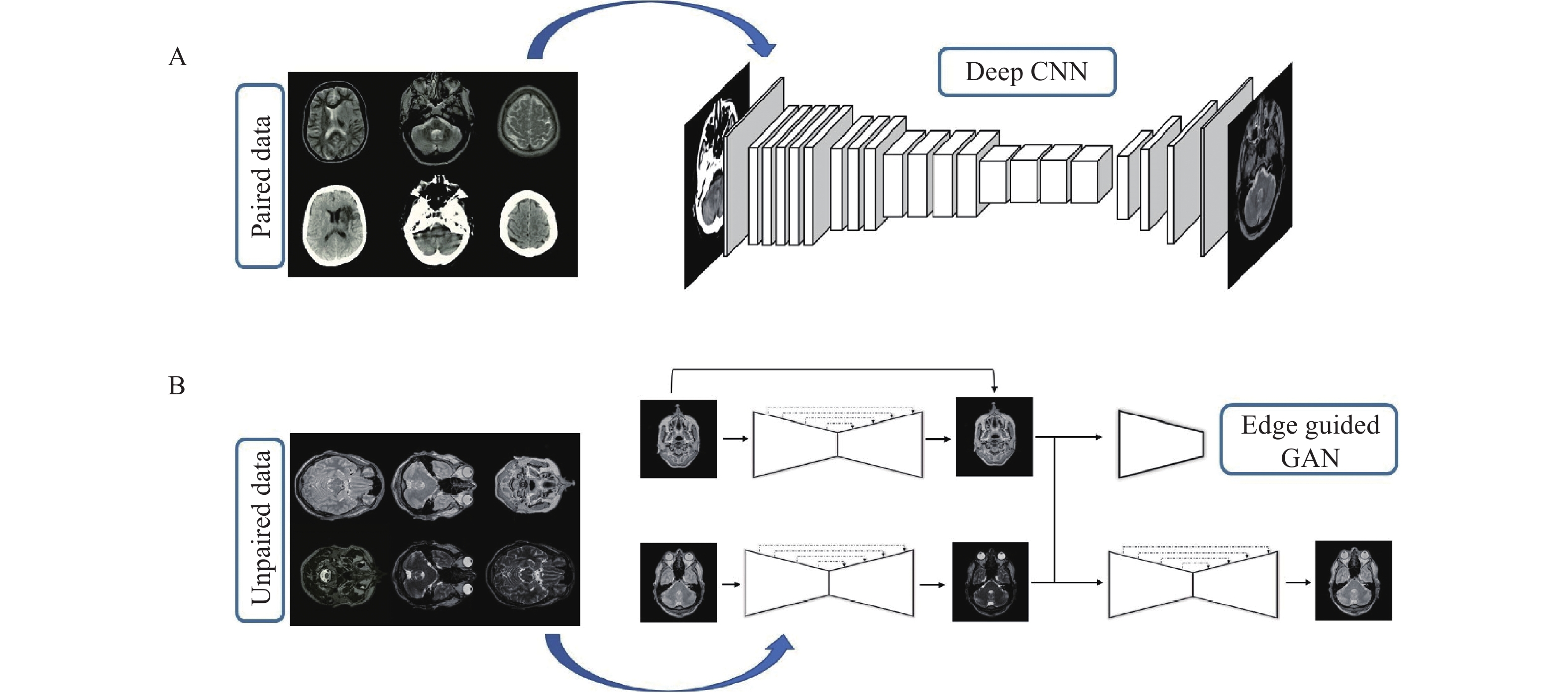
In this section, the proposed deep framework for medical image-to-image translation is presented. Fig. 1 provides a visual representation of the proposed deep framework for both paired and unpaired data by an example of the CT-MRI and T2-PD translation.
Figure
1.
Overview of the proposed framework.
A: The proposed deep CNN is suitable when the paired data is accessible; B: the proposed EGGAN is suitable when the provided data is unpaired. CNN: convolutional neural network; GAN: generative adversarial network; EGGAN: edge-guided generative adversarial network.
Deep neural network with global to local feature fusion
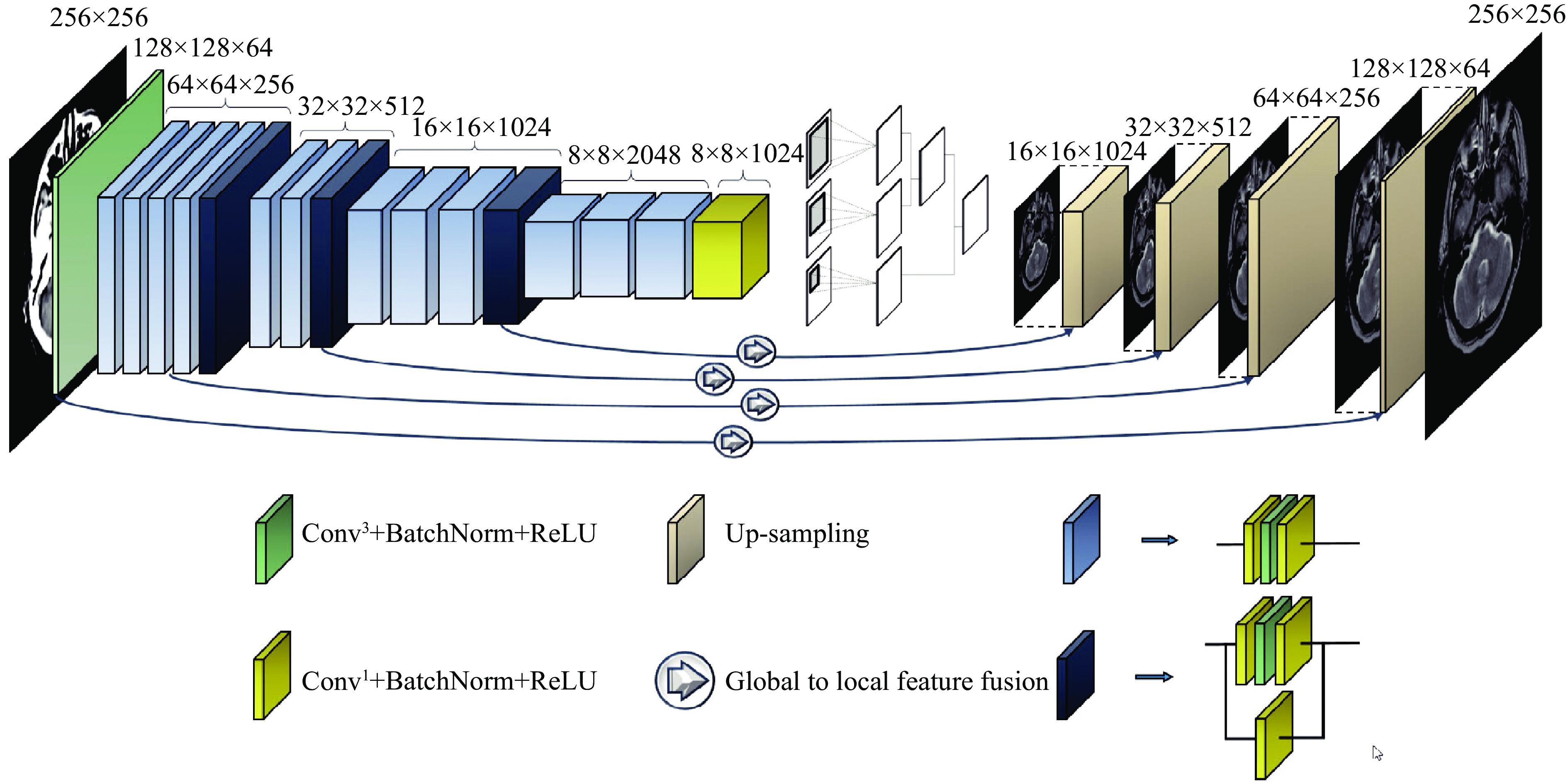
This network is proposed for image-to-image translation of paired data and has an encoder-decoder structure. The encoding part behaves as a traditional convolutional neural network (CNN) that learns to extract various robust and complex features using different scales from input images. In the ResNet[10], the size of feature maps directly decreases to ¼ of the size after applying a pooling layer that is unsuitable, and local information of the feature maps with half the size (i.e., 128×128) of the input image is required. This provides a convolutional layer in place of a pooling layer (Fig. 2). Fully connected layers are removed to reduce the number of tunable parameters. Accordingly, the size of generated feature maps after passing through the encoding part of the network is (8×8) (Fig. 2). However, the continuous residual blocks of deep learning ensure abundant features can be extracted and reduce the difficulty of training a deep network.
Figure
2.
The proposed deep encoder-decoder network for image-to-image translation of medical paired data.
Conv3: the convolutional layer with 3×3 kernel size; Conv1: the convolutional layer with 1×1 kernel size; BatchNorm: the batch normalization layer; ReLU: rectified linear unit.
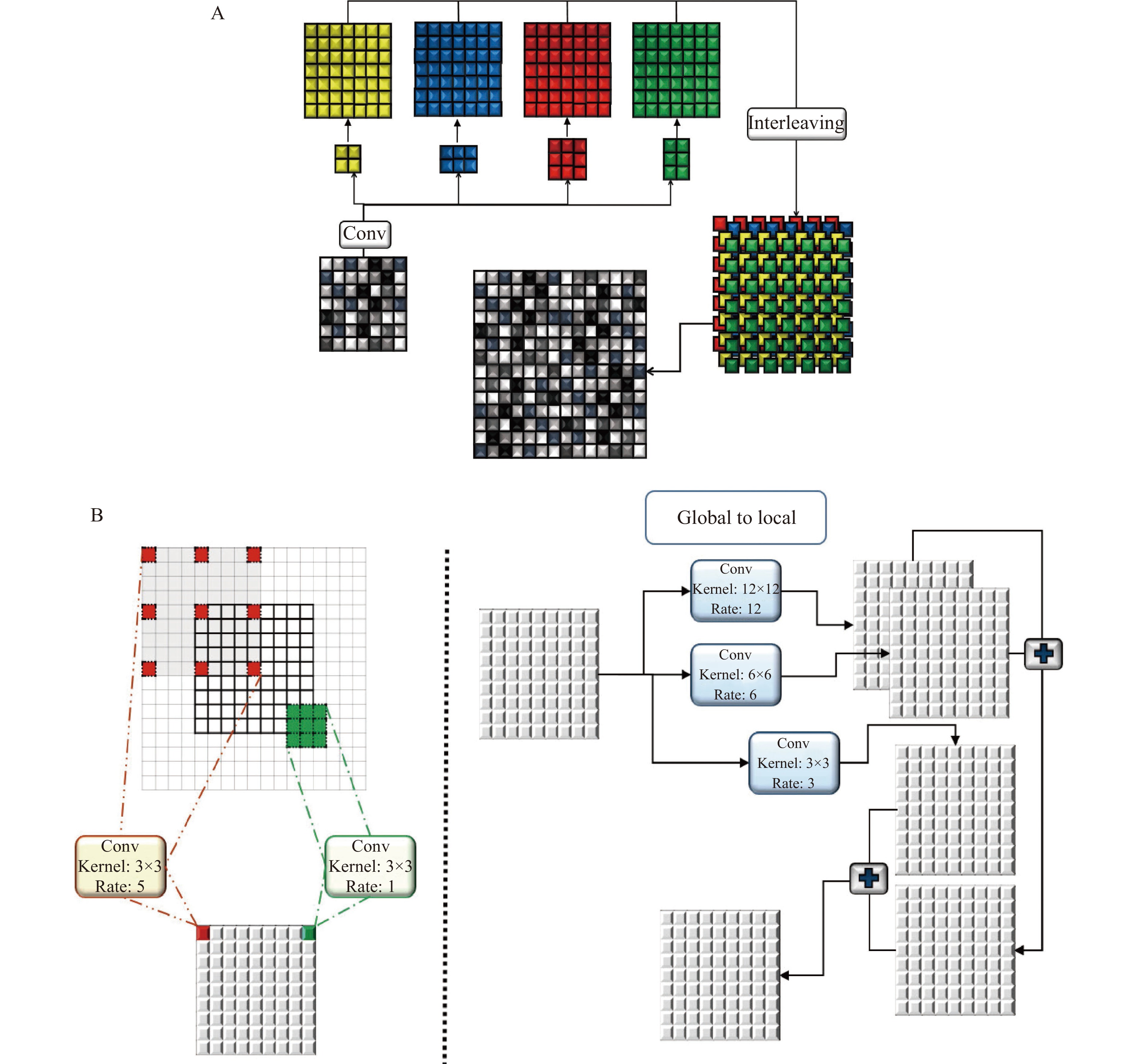
During decoding, generated coarse feature maps are transformed and the target image is gradually reconstructed from a low to high resolution. Reconstructing the target with a detailed image from the generated abstract low resolution is particularly difficult[20]. An up-sampling method is implemented to double the size of the feature maps at each level of the network. This method has two branches. In the first branch, four convolutional layers, 2×2, 3×2, 2×3, and 3×3, are applied to layers and results are interleaved to generate a feature map with doubled size. This procedure is repeated in the second branch with the difference that a 5×5 convolutional layer is applied. Finally, the results of the first and second layers are fused (Fig. 3A).
Figure
3.
The structure of the utilized up-sampling and global to local feature fusion.
A: Procedure of the employed up-sampling; B: procedure of the dilated convolution with different dilated rates (left) and structure of the proposed global to local feature fusion approach. Conv: the convolutional layer.
Estimating target images using an image with a different domain is a complex task that requires local and global information from the input image, simultaneously. Context information of different scales should be fused to model the dependency between different tissues and their surroundings in medical images. Hence, a global-to-local feature fusion strategy is proposed to address this issue (see Fig. 2). This strategy is based on the dilated convolutional operation[21], which makes it possible to expand the receptive field without increasing the number of parameters (Fig. 3B). The general form of discrete convolutions is defined according to equation (1):
(P∗tl)(s)=∑a+tb=sP(a)k(b),
(1)
where ωr=[−r,r]2∩Z2, F:Z2→R, l:ωr→R, and t is the dilation rate[21].
In the proposed strategy, a series of dilation rates (3, 6, and 12) is selected and employed to produce multi-scale feature maps. After applying dilated convolution, the size of generated feature maps should remain unchanged, which requires carefully selecting a padding rate in accordance with the dilated rate. The higher the dilation rate, the more general the information contained will be, with wider visual cues in the produced feature maps. Therefore, generated low and high-level context information is progressively aggregated. This procedure is carried out using the highest level of context information which is produced by the largest dilated rate to the lowest-level feature maps that are produced by the smallest dilated rate (ln). The procedure of extracting and fusing (⊕) the feature maps (P) with different context information is described in equation (2):
φ=P∗tl1⊕⋯⊕[P∗tln−2⊕[P∗tln−1⊕[P∗tln]]].
(2)
Proposed edge-guided GAN for unpaired data
This network is proposed for image-to-image translation of unpaired data and has a structure based on the GAN. The basic structure of the proposed edge-guided GAN is represented in Fig. 4 with an example of the CT-MRI translation. As shown in Fig. 4, the proposed model has three main elements including the generator, edge detector, and discriminator. The generator learns to generate fake images by incorporating feedback from the discriminator. The proposed encoder-decoder network is utilized as the generator.
Figure
4.
The proposed deep for image-to-image translation of unpaired medical data.
The process of training the network by unpaired data and using different loss functions for different purposes is completely shown. GAN: generative adversarial network.
The discriminator tries to decide whether the results produced by the generator are considered the target. PatchGAN[22] is used as a discriminator in a consistent manner with the original CycleGAN, which is a multi-layer CNN for feature extraction and classification. Edges are important parts of an image, which is vital for accurate image retrieval. Hence, the edge detection network is employed to modify structural estimates by analyzing image edges of the input domain. A network-based upon U-Net[23] is trained using images and their corresponding edges, which are extracted by a canny edge detector. The trained network with fixed weights is used in the proposed EGGAN for computing the edge maintenance loss.
Edge-based loss function
The loss function guides the training procedure of a deep neural network to obtain accurate results. This function computes the difference between real target images and approximated images[24]. Determining the appropriate loss function according to the desired purpose of the network is very important. Edges are crucial parts of image content, and play an important role in image reconstruction. Therefore, edges should be well-maintained to enhance the visual appearance of the image content. Hence, the loss functions of the proposed deep networks for paired and unpaired data are determined in such a way that the edges of tissue images are used in image-to-image translation as well as image reconstruction.
The loss function of the proposed deep encoder-decoder network for image-to-image translation contains three criteria, including the L2 norm (eL2), gradient (eG), and normal values (eN). The L2 norm is suitable for removing the overall shift in the estimated image in the target domain. The gradient and normal values are very sensitive to small shifts in tissue edges seen in medical images.
where ge is the value of the estimated target image, gr is the value of the reference target image, {\nabla _x} is a derivation in the x-direction, {\nabla _y} is a derivation in the y-direction, {n_{{d_e}}} is \left[ {{\nabla _x}({g_e}),{\nabla _y}({g_e}),1} \right] , {n_{{d_r}}} is \left[ {{\nabla _x}({g_r}),{\nabla _y}({g_r}),1} \right] , and n is the total number of pixels.
The loss function of the proposed network for image-to-image translations of paired data contains two criteria, including edge maintenance and CycleGAN losses. The edge detector network (F) is used to extract the edge of the estimated images and reference images. Edge maintenance loss (eEM) is computed as the difference between the edges of the estimated images and reference images:
CycleGAN loss has three components, including cycle-consistency loss, GAN loss, and identity loss[19]. Identity loss is used to regulate the generator in order to avoid superfluous translation and ensure results are closer to the identity translation. Cycle-consistency loss constraints the mapping function space and makes it possible for the generator to decouple the style and content of input images. Additionally, cycle-consistency permission training is used for the proposed EGGAN, with unpaired data. The LSGAN[25] is used as the GAN loss.
where eCG is the CycleGAN loss; eCyc and eiden are the cycle-consistency and identity losses, respectively; λCyc and λiden are the weights of the cycle-consistency and identity losses, respectively; and λEM is the weight of the edge maintenance loss.
Dataset
Two datasets are utilized in this study, both of which have CT-MRI and PD-T2 paired data. These were used to analyze the proposed encoder-decoder network for paired data and the proposed EGGAN for unpaired data.
MRI-CT dataset
This dataset contains MRIs from 18 patients who were randomly selected. MRIs were obtained using a 1.5 T Siemens Avanto scanner using a T1-weighted 3D spoiled gradient (repetition time 11 milliseconds, echo time 4.6 milliseconds, field-of-view 256×256×160 mm3, and flip angle 20°). Related CT images were obtained using a Siemens Sensation 16 scanner with tube voltage 120 kV, in-plane resolution 0.5×0.5 mm2, exposure 300 mAs, and slice thickness of 1 mm (https://github.com/ChengBinJin/MRI-to-CT-DCNN-TensorFlow).
IXI dataset
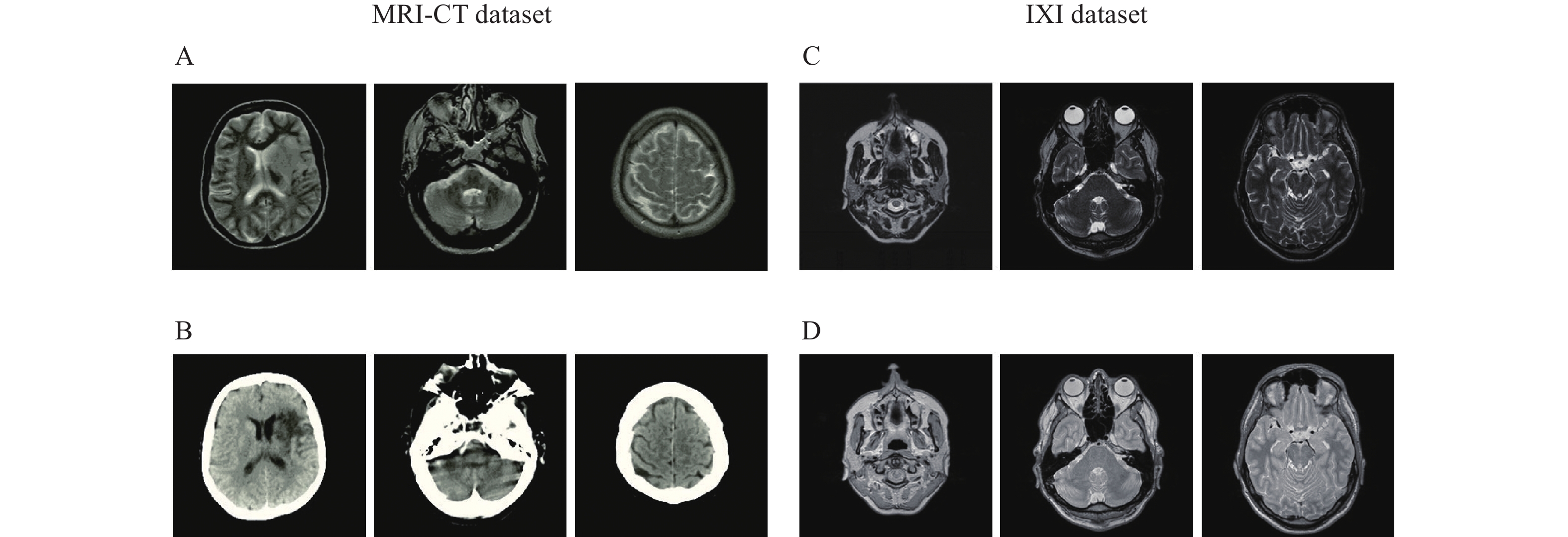
This dataset contains nearly 600 MRIs from relatively healthy participants, which were collected by three different hospitals in London including the Hammersmith Hospital which used a Philips 3T system, Guy's Hospital which used a Philips 1.5T system, and the Institute of Psychiatry which used a GE 1.5T system. PD and T2 images obtained using the Philips Medical Systems Gyroscan Intera 1.5T have the following parameters: repetition time 8178 milliseconds, echo train length 16, number of phase encoding steps 187, and flip angle 90° (http://brain-development.org/ixi-dataset). PD and T2 images obtained using the Philips Medical Systems Intera 3T have the following parameters: repetition time 5725 milliseconds, echo train length 16, number of phase encoding steps 187, acquisition matrix 192×187, and flip angle 90°. Fig. 5 represents certain samples of the utilized datasets.
Figure
5.
Certain samples of the utilized dataset for implementing the proposed encoder-decoder network.
A: T1 weighted image of the MRI-CT dataset; B: CT image of the MRI-CT dataset; C: T2 weighted image of IXI dataset; D: PD image of the IXI dataset. MRI-CT: magnetic resonance imaging-computed tomography; PD: proton density.
In this section, an assessment of results from the proposed image-to-image translation are reported. Computations have been carried out using a single NVIDIA GeForce GTX 1080 Ti with 11 GB of GPU memory.
Quality assessment
Criteria used for analyzing the performance of the proposed deep networks are defined in this section. There is no consensus within the scientific community regarding criteria for assessing the performance of the models studied here[26]. Therefore, four different criteria including peak-signal-to-noise-ratio (EPSNR)[27], mean absolute error (EMAE), root-mean-squared error (ERMSE), and structural similarity index measure (ESSIM)[28] were used, and were computed by comparing the estimated target image values with corresponding values in the reference data[18,29].
where μ and σ are the mean and variance of the considered variable.
Paired image-to-image translation
In this section, the results from the proposed encoder-decoder network under different scenarios are presented. Four challenging image-to-image translations including CT-MRI, MRI-CT, T2-PD, and PD-T2 are selected. In the T2-PD and PD-T2 translation, the imaging modality is the same, and the acquired contrast values are different because of the procedure of data collection. At the same time, in the CT-MRI and MRI-CT translations, the imaging modality of the data is different, which makes the issue more difficult and challenging. Additionally, the proposed network is utilized for eliminating motion effects from the medical MR images and translating these into corresponding motion-free images.
In the CT-MRI and MRI-CT translation, images from 9 patients are selected as training data and images of the remaining 9 patients are selected as test data. As each image volume has approximately 150 slices, approximately 2700 training and testing samples are provided.
In the PD-T2 and T2-PD translation, images from 60 patients are employed and half of those are used as training data while the remaining thirty were selected as test data. These images have approximately 130 slices, resulting in 7800 training and testing samples.
In the motion correction procedure, T1 images from 40 patients are utilized and the motion artifacts are generated upon those. After which, the provided paired images are divided into two same-size groups for both training and testing. As the T1 image has approximately 150 slices, approximately 6000 samples are provided for implementation.
All the provided images are resampled to 256×256 pixels and the following data augmentation was applied to all datasets.
• Translation: the batch data are horizontally and vertically flipped with 0.5 probability;
• Flip: a certain part of the batch data is randomly cropped;
• Rotation: the batch data are rotated by \theta \in [ - {5^ \circ },{5^ \circ }]
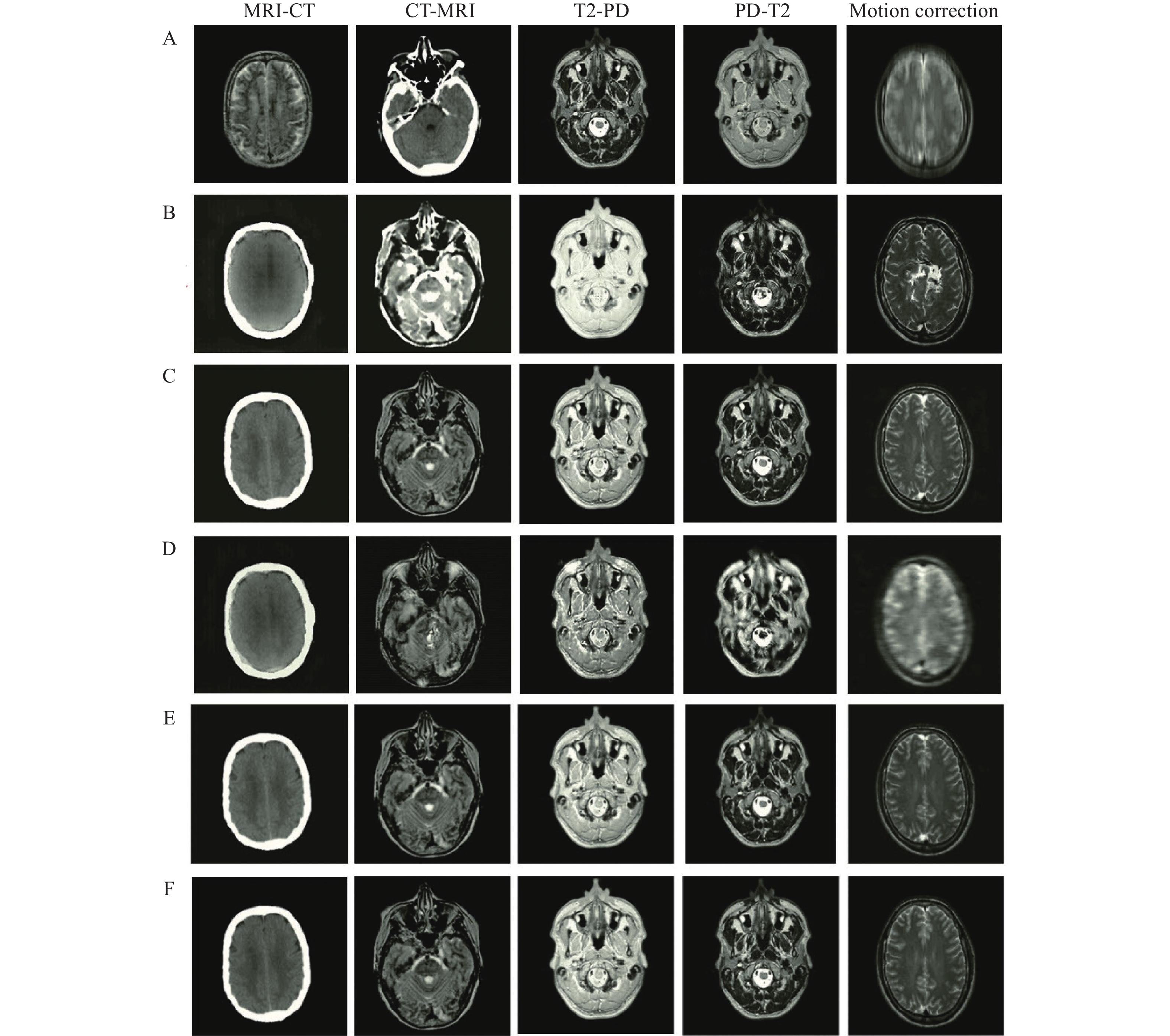
The number of epochs, batch size, momentum, and learning rate for the proposed encoder-decoder network in these tasks are considered to be 100, 2, 0.9, and 10−4, respectively. The performance of the proposed network is evaluated and compared with several well-known networks including CycleGAN[19], uncertainty-guided progressive generative adversarial network (UPGAN)[14], registration generative adversarial network (RegGAN)[30], and Pix2Pix[22]. It should be noted that the number of epochs are learning rate are selected by cross validation. The performance is analyzed on the five mentioned tasks (MRI-CT, CT-MRI, T2-PD, PD-T2, and Motion correction). In this regard, different numbers of epoch in the set (20, 40, ···, 100) and learning rates in the set (10−5, 5×10−5, 10−4, 5×10−4, 10−3) are investigated. The result of image-to-image translations using the proposed network and other mentioned networks in different tasks is represented in Fig. 6. The results of the mentioned criteria are reported in Table 1.
Figure
6.
Visual comparison of the proposed encoder-decoder network for paired image-to-image translation with some commonly used deep networks in the designed tasks.
According to Fig. 6, the edges and structure of the obtained results using the Pix2Pix and CycleGAN networks are different from the reference data, which indicates an inability of these networks to retrieve boundary and structural information. Additionally, the achieved intensity values using CycleGAN and RegGAN are very different from reference data. Although the obtained results of UPGAN are relatively suitable for different tasks, their quality and sharpness are lower than those in the proposed network. Employing the global-to-local feature fusion strategy significantly improves the structure of results. Using a loss function also emphasizes edges which improves the sharpness and quality of tissue boundaries (Fig. 6).
The evaluation (Table 1) highlighted a better performance of the proposed encoder-decoder network across all criteria. Of course, during image translation MRI-CT and CT-MRI, inputs and outputs belong to different domains. However, for T2-PD and PD-T2, the inputs and outputs belong to the same domain and the recorded intensity values are different. The translation between two different domains (MRI-CT and CT-MRI) is much more challenging than the conversion of intensity values used in T2-PD and PD-T2. The effect of this can be observed in the results of the UPGAN, CycleGAN, RegGAN, and Pix2Pix modeling (Table 1).
In the results obtained from the proposed network, translations between two different domains are not significantly reduced compared to the translation of intensity values. This is due to the power structure of the proposed network in feature extraction, feature integration, and data retrieval. It should be noted that the higher the values for ERMSE and EMAE, the greater the error of the obtained results. Likewise, the higher the values for EPSNR and ESSIM, the greater the accuracy of the results obtained.
Unpaired image-to-image translation
In this section, the performance of the proposed EGGAN is evaluated for image-to-image translation using unpaired data. The aforementioned scenarios were re-implemented using unpaired data. The selected training and test data for different scenarios in the previous section are utilized. Only target images are shuffled so that they are not paired with input images. The number of epochs, batch size, momentum, and learning rate for the proposed EGGAN in these tasks are considered to be 100, 4, 0.9, and 5×10−4, respectively. It should be noted that the number of epochs, learning rate, λCyc, λiden, and λEM are selected by cross validation. The number of epochs and learning rate are specified the same as paired translation.
Different λCyc, λiden, and λEM in the set [1, 2, 5, 10, 20] are analyzed, and λCyc=10, λiden=10, and λEM=5 are determined for all experiments. As in the previous section for paired analysis, the performance of the proposed EGGAN was evaluated and compared with several well-known networks dealing with unpaired data including, CycleGAN[19], AGAN[31], and RegGAN[30]. Certain samples of image-to-image translation of unpaired data are presented in Fig. 7 and the quantitative evaluation is reported in Table 2.
Figure
7.
Visual comparison of the proposed edge-guided generative adversarial network for unpaired image-to-image translation with some common deep networks in the designed tasks.
According to Fig. 7, one can see that proper edge retrieval is a major problem for image translation using unpaired training data. This increases the error of CycleGAN, AGAN, and RegGAN networks, especially in motion correction where edges are distorted, and accurate reconstruction of the edges is very important. This also occurs in translation between two different domains (MRI-CT and CT-MRI), where the boundaries of the target should be estimated. An attempt was made to overcome these issues by employing the proposed encoder-decoder network as the generator and using an edge-based loss function to estimate accurate results and preserve the tissue boundaries.
Our evaluation (Table 2) demonstrates that the proposed EGGAN outperforms other networks. Although unpaired training data was used, the proposed network is still successful in estimating the values. As a result, by using the EGGAN, high accuracy can be achieved if there is no available paired data.
The quantitative analysis of the trained network with paired and unpaired data performed similarly well (Table 1 and 2). For the visual analysis, the results of the trained encoder-decoder network by paired training data and the trained EGGAN by unpaired training data are compared in Fig. 8. This figure exhibits a 1D profile passing through three red lines including the ground truth data, images estimated using the encoder-decoder network trained by paired data, and images estimated using the EGGAN trained by unpaired data. A different image was computed by subtracting the ground truth images and estimated images. A comparison of the 1D profiles and an analysis of their ascent and descent trends show great closeness and similarity of the translated images using the trained networks by paired and unpaired data. The generated difference maps show slight errors in some parts for the estimated images.
Figure
8.
Comparison of the proposed network for paired and unpaired image-to-image translation in the designed tasks.
A: MRI to CT; B: CT to MRI; C: T2 to PD; D: PD to T2; and E: T2 to PD. Moreover, the difference images between estimated paired and unpaired training data and reference images are computed. MRI: magnetic resonance imaging; CT: computed tomography; PD: proton density.
In this study which included a comprehensive evaluation of the proposed framework, three different image-to-image translation scenarios were designed and implemented. In the first scenario, the goal was to translate MRI products, i.e., PD to T2 and T2 to PD. In this scenario, the geometry and structure of input and output images were the same. Yet, intensity values were different owing to differences in the way the images were provided. In the second scenario, the goal was to translate input images to images of a different domain, i.e., MRI to CR and CT to MRI. In this scenario, in addition to the intensity values in the two images, the geometric structure of the images is also different, which poses a more substantial challenge. In the third scenario, the goal was to eliminate errors created during imaging, e.g., the motion artifact. In this case, the intensity values were relatively similar, but the geometry of the image has changed due to errors.
The performances of the proposed networks for paired and unpaired training data were evaluated quantitatively (Fig. 6 and 7 as well as Table 1 and 2). According to the achieved EMAE, ERMSE, EPNSR, and ESSIM (Table 1 and 2), the proposed encoder-decoder network for paired training data and the proposed EGGAN for unpaired training data achieved the best performance against the other networks in all the designed translation tasks. This may be partially due to the fact that some hidden details of the input images were unrecognizable to the generators of these models and produce some fake details to match their loss functions. Hence, these fake details reduce their accuracy and make the results worse than the results of the EGGAN. Indeed, in the generator for the EGGAN model, the details are extracted using the proposed global to local feature fusion strategy.
According to the difference map of the ground truth and the corresponding estimated images (Fig. 8), the errors in the CT-MRI and MRI-CT translations are the outer boundaries of the head area. This may be partially attributed to imperfect alignment between the MRI and CT images. In the other translations (PD-T2, T2-PD, and motion correction), the proposed networks with edge-based loss learn to distinguish different anatomical structures in the head area from similar input pixel values. It is challenging to obtain correspondence pixels between the MRIs and CT images by a linear registration[1]. This causes inaccuracies in the model during the training procedure. The cross-modality registration problem is converted into a single modality registration problem by converting the CT-MRI and MRI-CT in which the inputs and outputs belong to different modalities.
Most medical image translation methods use paired data for network training[11–12,15,32–36], and a limited number of methods focus on using unpaired data[16,37]. One of the strengths of the proposed deep framework is to present a network capable of training using unpaired data for medical image translation. In addition, the performance of the proposed network was examined and analyzed in different scenarios. Research in this field, especially research related to image translation using unpaired data, a specific translation (MRI to CT) has been considered[16,37]. Additionally, in the proposed deep neural network an edge-guided strategy was considered to improve the accuracy of the achieved results, especially for tissue boundaries. This is very important for diagnosis, although in most of the existing methods simple U-Net and GAN are used without considering edge information[38–42]. Finally, a global-to-local feature fusion strategy was proposed instead of using simple skip connections[1,38–39,41,43–44]. This enabled us to extract various robust features through down-sampling as well as to used these during the up-sampling procedure. Investigating the 3D architecture of deep neural networks for the analysis of 3D multi-channel volumes will be suggested for future work.
Table
1.
Performance analysis and quantitative comparison of the proposed encoder-decoder network for paired image-to-image translation with some common deep networks in the designed tasks
Table
2.
Performance analysis and quantitative comparison of the proposed EGGAN for unpaired image-to-image translation with some common deep networks in the designed tasks
Han X. MR-based synthetic CT generation using a deep convolutional neural network method[J]. Med Phys, 2017, 44(4): 1408–1419. doi: 10.1002/mp.12155
[2]
Catana C, Van Der Kouwe A, Benner T, et al. Toward implementing an MRI-based PET attenuation-correction method for neurologic studies on the MR-PET brain prototype[J]. J Nucl Med, 2010, 51(9): 1431–1438. doi: 10.2967/jnumed.109.069112
[3]
Chen Y, Juttukonda M, Su Y, et al. Probabilistic air segmentation and sparse regression estimated pseudo CT for PET/MR attenuation correction[J]. Radiology, 2015, 275(2): 562–569. doi: 10.1148/radiol.14140810
[4]
Uh J, Merchant TE, Li Y, et al. MRI-based treatment planning with pseudo CT generated through atlas registration[J]. Med Phys, 2014, 41(5): 051711. doi: 10.1118/1.4873315
[5]
Keereman V, Fierens Y, Broux T, et al. MRI-based attenuation correction for PET/MRI using ultrashort echo time sequences[J]. J Nucl Med, 2010, 51(5): 812–818. doi: 10.2967/jnumed.109.065425
[6]
Zheng W, Kim JP, Kadbi M, et al. Magnetic resonance–based automatic air segmentation for generation of synthetic computed tomography scans in the head region[J]. Int J Radiat Oncol Biol Phys, 2015, 93(3): 497–506. doi: 10.1016/j.ijrobp.2015.07.001
[7]
Huynh T, Gao Y, Kang J, et al. Estimating CT image from MRI data using structured random forest and auto-context model[J]. IEEE Trans Med Imaging, 2016, 35(1): 174–183. doi: 10.1109/TMI.2015.2461533
[8]
Zhong L, Lin L, Lu Z, et al. Predict CT image from MRI data using KNN-regression with learned local descriptors[C]//2016 IEEE 13th International Symposium on Biomedical Imaging (ISBI). Prague: IEEE, 2016: 743–746.
[9]
Krizhevsky A, Sutskever I, Hinton GE. Imagenet classification with deep convolutional neural networks[C]//Proceedings of the 25th International Conference on Neural Information Processing Systems. Lake Tahoe: ACM, 2012: 1097–1105.
[10]
He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770–778.
[11]
Nie D, Trullo R, Lian J, et al. Medical image synthesis with deep convolutional adversarial networks[J]. IEEE Trans Biomed Eng, 2018, 65(12): 2720–2730. doi: 10.1109/TBME.2018.2814538
[12]
Dar SU, Yurt M, Karacan L, et al. Image synthesis in multi-contrast MRI with conditional generative adversarial networks[J]. IEEE Trans Med Imaging, 2019, 38(10): 2375–2388. doi: 10.1109/TMI.2019.2901750
[13]
Kearney V, Ziemer BP, Perry A, et al. Attention-aware discrimination for MR-to-CT image translation using cycle-consistent generative adversarial networks[J]. Radiol Artif Intell, 2020, 2(2): e190027. doi: 10.1148/ryai.2020190027
[14]
Upadhyay U, Chen Y, Hepp T, et al. Uncertainty-guided progressive GANs for medical image translation[C]//24th International Conference on Medical Image Computing and Computer Assisted Intervention. Strasbourg: Springer, 2021: 614–624.
Yang H, Sun J, Carass A, et al. Unpaired brain MR-to-CT synthesis using a structure-constrained CycleGAN[C]//4th International Workshop on Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support. Granada: Springer, 2018: 174–182.
[17]
Jin C, Kim H, Liu M, et al. Deep CT to MR synthesis using paired and unpaired data[J]. Sensors, 2019, 19(10): 2361. doi: 10.3390/s19102361
[18]
Wolterink JM, Dinkla AM, Savenije MHF, et al. Deep MR to CT synthesis using unpaired data[C]//Second International Workshop on Simulation and Synthesis in Medical Imaging. Québec City: Springer, 2017: 14–23.
[19]
Zhu J, Park T, Isola P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]//Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 2242–2251.
[20]
Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 3431–3440.
[21]
Yu F, Koltun V. Multi-scale context aggregation by dilated convolutions[C]//4th International Conference on Learning Representations. San Juan: ICLR, 2016.
[22]
Isola P, Zhu J, Zhou T, et al. Image-to-image translation with conditional adversarial networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 5967–5976.
[23]
Ronneberger O, Fischer P, Brox T. U-Net: convolutional networks for biomedical image segmentation[C]//18th International Conference on Medical Image Computing and Computer-Assisted Intervention. Munich: Springer, 2015: 234–241.
[24]
Rosasco L, De Vito E, Caponnetto A, et al. Are loss functions all the same?[J]. Neural Comput, 2004, 16(5): 1063–1076. doi: 10.1162/089976604773135104
[25]
Mao X, Li Q, Xie H, et al. Least squares generative adversarial networks[C]//Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 2813–2821.
[26]
Borji A. Pros and cons of GAN evaluation measures[J]. Comput Vis Image Und, 2019, 179: 41–65. doi: 10.1016/j.cviu.2018.10.009
[27]
Sheikh HR, Bovik AC. Image information and visual quality[J]. IEEE Trans Image Process, 2006, 15(2): 430–444. doi: 10.1109/TIP.2005.859378
[28]
Wang Z, Bovik AC, Sheikh HR, et al. Image quality assessment: from error visibility to structural similarity[J]. IEEE Trans Image Process, 2004, 13(4): 600–612. doi: 10.1109/TIP.2003.819861
[29]
Li W, Li Y, Qin W, et al. Magnetic resonance image (MRI) synthesis from brain computed tomography (CT) images based on deep learning methods for magnetic resonance (MR)-guided radiotherapy[J]. Quant Imaging Med Surg, 2020, 10(6): 1223–1236. doi: 10.21037/qims-19-885
[30]
Kong L, Lian C, Huang D, et al. Breaking the dilemma of medical image-to-image translation[C]//Proceedings of the 35th conference on Neural Information Processing Systems. Online: NIPS, 2021: 1964–1978.
[31]
Tang H, Liu H, Xu D, et al. AttentionGAN: unpaired image-to-image translation using attention-guided generative adversarial networks[EB/OL]. [2021-09-02]. https://doi.org/10.1109/TNNLS.2021.3105725.
[32]
Armanious K, Jiang C, Fischer M, et al. MedGAN: medical image translation using GANs[J]. Comput Med Imaging Graph, 2020, 79: 101684. doi: 10.1016/j.compmedimag.2019.101684
[33]
Ben-Cohen A, Klang E, Raskin SP, et al. Virtual PET images from CT data using deep convolutional networks: initial results[C]//Second International Workshop on Simulation and Synthesis in Medical Imaging. Québec City: Springer, 2017: 49–57.
[34]
Cui Y, Han S, Liu M, et al. Diagnosis and grading of prostate cancer by relaxation maps from synthetic MRI[J]. J Magn Reson Imaging, 2020, 52(2): 552–564. doi: 10.1002/jmri.27075
[35]
Denck J, Guehring J, Maier A, et al. MR-contrast-aware image-to-image translations with generative adversarial networks[J]. Int J Comput Ass Radiol Surg, 2021, 16(12): 2069–2078. doi: 10.1007/s11548-021-02433-x
[36]
Dinh PH. Multi-modal medical image fusion based on equilibrium optimizer algorithm and local energy functions[J]. Appl Intell, 2021, 51(11): 8416–8431. doi: 10.1007/s10489-021-02282-w
[37]
Wolterink JM, Leiner T, Viergever MA, et al. Generative adversarial networks for noise reduction in low-dose CT[J]. IEEE Trans Med Imaging, 2017, 36(12): 2536–2545. doi: 10.1109/TMI.2017.2708987
[38]
Florkow MC, Zijlstra F, Willemsen K, et al. Deep learning–based MR-to-CT synthesis: the influence of varying gradient echo–based MR images as input channels[J]. Magn Reson Med, 2020, 83(4): 1429–1441. doi: 10.1002/mrm.28008
[39]
Koike Y, Akino Y, Sumida I, et al. Feasibility of synthetic computed tomography generated with an adversarial network for multi-sequence magnetic resonance-based brain radiotherapy[J]. J Radiat Res, 2020, 61(1): 92–103. doi: 10.1093/jrr/rrz063
[40]
Liu Y, Lei Y, Wang T, et al. CBCT-based synthetic CT generation using deep-attention cycleGAN for pancreatic adaptive radiotherapy[J]. Med Phys, 2020, 47(6): 2472–2483. doi: 10.1002/mp.14121
[41]
Qi M, Li Y, Wu A, et al. Multi-sequence MR image-based synthetic CT generation using a generative adversarial network for head and neck MRI-only radiotherapy[J]. Med Phys, 2020, 47(4): 1880–1894. doi: 10.1002/mp.14075
[42]
Tie X, Lam SK, Zhang Y, et al. Pseudo-CT generation from multi-parametric MRI using a novel multi-channel multi-path conditional generative adversarial network for nasopharyngeal carcinoma patients[J]. Med Phys, 2020, 47(4): 1750–1762. doi: 10.1002/mp.14062
[43]
Gozes O, Greenspan H. Bone structures extraction and enhancement in chest radiographs via CNN trained on synthetic data[C]//2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI). Iowa City: IEEE, 2020: 858–861.
[44]
Yuan N, Dyer B, Rao S, et al. Convolutional neural network enhancement of fast-scan low-dose cone-beam CT images for head and neck radiotherapy[J]. Phys Med Biol, 2020, 65(3): 035003. doi: 10.1088/1361-6560/ab6240
Table
1.
Performance analysis and quantitative comparison of the proposed encoder-decoder network for paired image-to-image translation with some common deep networks in the designed tasks
Table
2.
Performance analysis and quantitative comparison of the proposed EGGAN for unpaired image-to-image translation with some common deep networks in the designed tasks
 Authors and Reviewers
Authors and Reviewers

 DownLoad:
DownLoad: